
Ga0's
SQLD_반정규화 본문
반정규화와 성능
1. 정의
▪ 정규화된 엔터티, 속성 관계에 대해 시스템의 성능 향상과 개발과 운영의 단순화를 위하여 중복을 허용하고, 조인을 줄이는 데이터 모델링 기법이다.
▪ 반정규화는 데이터 무결성이 깨질 수 있는 위험을 감수하고 조회(SELECT) 속도를 향상시키지만, 데이터 모델의 유연성은 낮아진다.
▪ 반정규화를 하면,
▫ 디스크 I/O량이 감소
▫ 경로가 먼 조인으로 인한 성능 저하를 해결
▫ 중복성의 원리를 활용하여 데이터 조회시 성능을 향상
▪ 즉, 아래와 같은 경우에 반정규화를 수행하면 좋다.
▫ 디스크 I/O 양이 너무 많아서 성능이 저하된 경우
▫ 경로가 너무 멀어 조인으로 인한 성능이 저하된 경우
▫ 칼럼을 계산하여 읽을 때 성능이 저하된 경우
▫ 다량의 범위를 자주 처리해야하는 경우
▫ 특정 범위의 데이터만 자주 처리하는 겨우
▫ 요약/집계 정보가 자주 요구되는 경우
→ 최근에 변경돤 값만을 조회할 경우 과도한 조인으로 인해 성능이 저하되어 나타난다.
→ 프로젝트 설계 단계에서 반정규화를 적용한다. (구축 및 시험단계에서 적용시 노력 비용이 증가...)
2. 적용 방법 절차
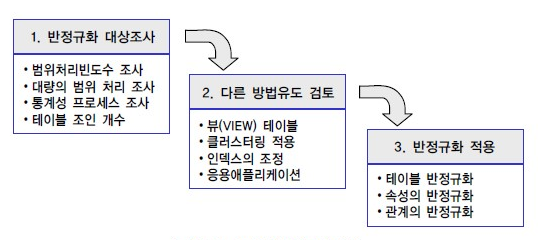
1) 반 정규화 대상 조사
▫ 범위처리 빈도수 조사, 대량의 범위 처리 조사, 통계성 프로세스 조사, 테이블 조인 개수 조사
2) 다른 방법 검토
▫ 반 정규화를 실행하기 전 다른 방법 검토, 클러스터링, 뷰 테이블, 인덱스 조정 , 응용애플리케이션, 파티션 등을 검토
▫ 파티션 : 대용량의 테이블을 여러 개의 데이터 파일에 분리해 저장
3) 반정규화 실행
▫ 테이블, 속성, 관계 등을 반정규화
3. 기법
▪ 테이블 반정규화
▫ 테이블 병합
- 1 : 1 관계 테이블 병합 : 1:1 관계를 통합하여 성능 향상
- 1 : M 관계 테이블 병합 : 1: M 관계를 통합하여 성능 향상
- 슈퍼/서브타입 테이블 병합 : 슈퍼/서브 관계를 통합하여 성능 향상
▫ 테이블 분할
- 수직 분할 : 컬럼단위의 테이블을 디스크 I/O를 분산처리 하기 위해 테이블을 1:1로 분리하여 성능향상한다. (트랜잭션이 처리되는 유형을 파악해야 한다.)
- 수평 분할 : 로우 단위로 집중 발생되는 트랜잭션을 분석하여 디스크 I/O 및 데이터 접근의 효율성을 높여 성능을 향상하기 위해 row 단위로 테이블을 쪼갬(관계가 없음)
▫ 테이블 추가
- 중복테이블 추가 : 다른 업무이거나 서버가 다른 경우 동일한 테이블 구조를 중복하여 원격 조인을 제거하여 성능을 향상
- 통계테이블 추가 : SUM, AVG 등을 미리 수행하여 계산해 둠으로써 조회 시 성능을 향상
- 이력테이블 추가 : 이력테이블 중에서 마스터 테이블에 존재하는 레코드를 중복하여 이력테이블에 존재하는 방법은 반정규화의 유형
- 부분테이블 추가 : 하나의 테이블의 전체 칼럼 중 자주 이용하는데 자주 이용하는 집중화된 칼럼이 있을 때 디스크 I/O를 줄이기 위해 해당 칼럼들을 모아놓은 별도의 반정규화된 테이블을 생성
▪ 칼럼반정규화
- 중복칼럼 추가 : 조인에 의해 처리할 때 성능저하를 예방하기 위해 즉, 조인을 감소시키기 위해 중복된 칼럼을 위치시킴
- 파생칼럼 추가 : 트랜잭션이 처리되는 시점에 계산에 위해 발생되는 성능저하를 예방하기 위해 미리 값을 계산하여 칼럼에 보관함, Derived Column이라고 함
- 이력테이블 칼럼추가 : 대량의 이력데이터를 처리할 때 불특정 날짜의 조회나 최근 값을 조회할 때 나타날 수 있는 성능저하를 예방하기 위해 이력테이블에 기능성 칼럼(최근값 여부, 시작과 종료일자 등)을 추가함
- PK에 의한 칼럼 추가 : 복합의미를 갖는 PK를 단일 속성으로 구성하였을 경우 발생된다. 단일 PK안에서 특정 값을 별도로 조회하는 경우 성능저하가 발생될 수 있는데, 이 때 이미 PK안에 데이터가 존재하지만 성능향상을 위해 일반속성으로 포함하는 방법이 PK에 의한 칼럼추가 반정규화
- 응용시스템 오작동을 위한 칼럼 추가 : 업무 적으로는 의미가 없지만 사용자가 데이터처리를 하다가 잘못 처리하여 원래 값으로 복구하기를 원하는 경우 이전 데이터를 임시적으로 중복하여 보관하는 기법, 칼럼으로 이것을 보관하는 방법은 오작동 처리를 위한 임시적인 기법이지만 이것을 이력데이터 모델로 풀어내면 정상적인 데이터 모델의 기법이 될 수 있음
* 이력 데이터는 단순히 쌓여 있는 과거의 데이터가 아니라 변경된 과거 데이터(예전에 쌓인 데이터여도 변경되지 않았다면 이력 데이터가 아니라 내역 데이터다.)
▪ 관계반정규화
- 중복 관계 추가 : 데이터를 처리하기 위한 여러 경로를 거쳐 조인이 가능하지만 이 때 발생할 수 있는 성능저하를 예방하기 위해 추가적인 관계를 맺는 방법이 관계의 반정규화
→ 테이블과 칼럼의 반정규화는데이터 무결성에 영향을 미치고,
관계의 반정규화는 데이터 무결성 깨뜨릴 위험이 없다. 데이터 처리 성능은 향상된다.
→ 정규화가 잘 정의된 데이터 모델에서 성능이 저하된 경우는 존재한다.

'Study IT > SQLD' 카테고리의 다른 글
| SQLD_데이터베이스 구조와 성능 (4) | 2023.05.03 |
|---|---|
| SQLD_대량 데이터에 따른 성능 (3) | 2023.04.30 |
| SQLD_정규화 (1) | 2023.04.28 |
| SQLD_성능 데이터 모델링의 개요 (3) | 2023.04.27 |
| SQLD_식별자 (1) | 2023.04.27 |



